## Why Site Monitoring Became a Core Discipline for Modern Web Operations
In the early days of the public web, a website going offline for a few minutes was often shrugged off as a minor inconvenience. That no longer works. For e-commerce, SaaS, media, finance, and public-sector services, even a short outage can mean lost revenue, broken customer trust, and compliance headaches. A 2023 Gartner estimate put the average cost of IT downtime at about $5,600 per minute for large enterprises, while newer outage studies have shown that high-impact incidents can climb far higher depending on industry and transaction volume. This is why **Site Monitoring** has moved from an optional admin task to an operational requirement. It is now tied directly to **Website Performance**, **Site Availability**, incident response, and customer experience. Teams no longer monitor only whether a homepage loads; they track latency, error rates, SSL expiration, DNS behavior, API health, and even third-party dependencies that can quietly break user journeys. ## What Site Monitoring Actually Measures Good monitoring is more than a green-or-red status light. It is a layered view of how a digital service behaves in the real world. ### Uptime, latency, and user experience At the most basic level, **Site Monitoring** checks whether a service responds within an expected time. That seems simple, but response time matters enormously. Research from Google has shown that as page load time rises from 1 second to 3 seconds, the probability of bounce can increase by 32%. Push that to 5 seconds, and the likelihood of user abandonment rises even more sharply. For high-traffic sites, those delays translate into measurable revenue loss. A robust monitoring setup will typically measure: – response time from multiple regions – HTTP status codes and error spikes – SSL certificate validity – DNS resolution time – JavaScript failures and front-end rendering issues – API availability and third-party service health ### Site Availability versus functional availability Many teams use “uptime” and **Site Availability** interchangeably, but there is an important distinction. A site may technically answer requests while still being effectively broken. Login forms may fail, checkout pages may time out, or the search function may return empty results. Functional availability is often the more meaningful metric because it reflects what users can actually do. This is especially important in industries with strict service commitments. SaaS vendors often advertise 99.9% or 99.99% availability. That sounds close, but the difference is real: 99.9% uptime allows roughly 43.8 minutes of downtime per month, while 99.99% reduces that to about 4.4 minutes. ## The Role of Domain Database Systems in Monitoring A reliable **Domain Database** is the foundation of internet naming, ownership, and lookup operations. Monitoring tools depend on domain data to verify registration status, nameserver configuration, expiration dates, registrar changes, and DNS record integrity. If a domain is about to expire, is hijacked, or has been misconfigured, users may see failures long before the application itself is affected. This became especially visible after several high-profile DNS and registrar incidents in the last decade, where service disruption came not from software bugs but from expired records, bad zone changes, or provider outages. In practice, a **Domain Database** helps teams answer questions such as: Who owns the domain? When does it expire? Which nameservers are authoritative? Has the DNS footprint changed unexpectedly? For security teams, that is crucial. Typosquatting, subdomain takeover, and unauthorized changes to DNS records can be detected faster when the domain layer is continuously monitored alongside application metrics. ## Real-world use cases across industries Banks and payment providers use monitoring to protect transaction flows and reduce fraud-related friction. If a payment gateway slows down by even a few hundred milliseconds, conversion rates can drop. Retailers lean on **Website Performance** data during peak periods like Black Friday or Singles’ Day, when traffic can spike by several hundred percent in minutes. Streaming platforms monitor regional reachability because routing issues in one CDN node can affect millions of users at once. Healthcare systems have another challenge: availability is not just commercial, it is operational. Patient portals, lab result systems, and telehealth platforms must remain reachable even when traffic patterns are unpredictable. Meanwhile, government services increasingly rely on **Site Monitoring** to maintain public access to tax portals, benefits systems, and emergency information pages. ## How modern monitoring tools work Most mature platforms combine synthetic checks with real-user monitoring. Website Health Synthetic tests simulate a visit from a specific region or device type, while real-user monitoring captures what actual visitors experience in the browser. Together, they provide both control and context. Modern stacks also correlate infrastructure signals. A spike in page latency may coincide with a database lock, a memory leak in an application server, or packet loss between a cloud region and a CDN edge. Observability platforms have grown quickly because teams want one timeline that connects logs, traces, metrics, and alerts. One practical pattern is to monitor the highest-risk journey first: 1. homepage and landing pages 2. login and authentication 3. search or catalog access 4. checkout, payment, or form submission 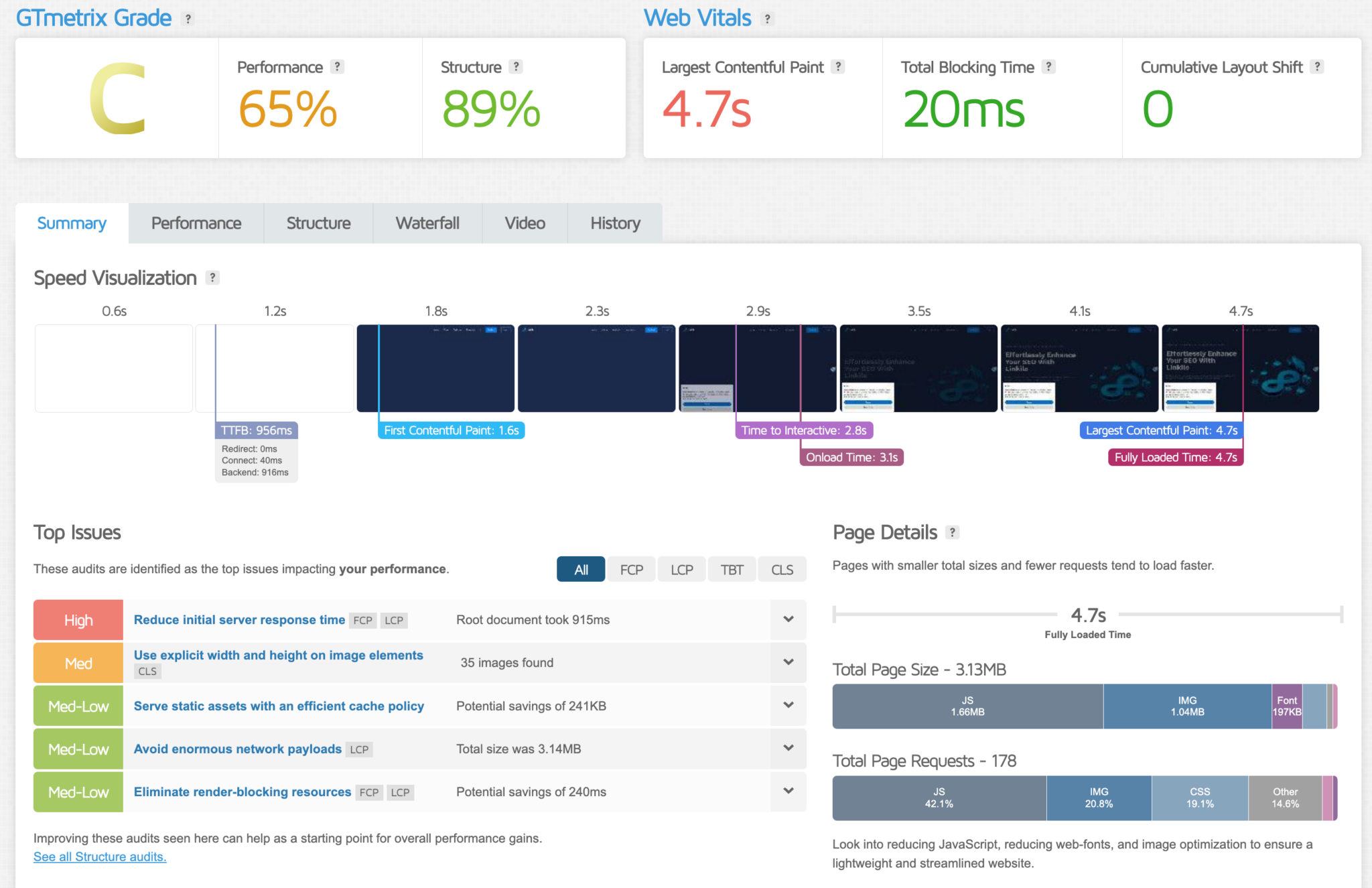 5. API endpoints used by mobile apps or partners That sequence reflects where business impact is usually greatest. ## Why domain intelligence and uptime data now intersect The internet used to separate infrastructure monitoring from domain administration. That split is fading. Attackers increasingly target the control plane: registrars, DNS records, certificates, and account recovery paths. At the same time, outages are often traced back to simple domain issues rather than deep application failures. This is where a well-maintained **Domain Database** becomes valuable beyond inventory. It supports asset management, renewal workflows, brand protection, and incident triage. If monitoring flags a sudden drop in **Site Availability**, teams can quickly verify whether the problem is rooted in hosting, DNS, or registrar status instead of wasting time on the wrong layer. ## What strong monitoring programs get right The best teams treat monitoring as an operational habit, not a dashboard accessory. They review false positives, tune thresholds by business criticality, and test alert routing regularly. They also align alerts with user impact, because a five-second slowdown on a marketing page matters less than a 500-millisecond delay on a payment API. A practical, resilient setup usually includes: – geographically distributed checks – alert escalation by severity – dependency mapping for third-party services – certificate and domain expiry warnings – performance baselines before major releases – incident review tied to customer outcomes ## The next phase: from detection to prediction The direction of the market is clear. Monitoring is shifting from simple detection to prediction. Machine learning is being used to identify anomaly patterns before they become incidents, and infrastructure teams are increasingly automating remediation for common failures. With cloud-native systems, where services may scale across regions in seconds, manual oversight alone is no longer enough. That does not mean human judgment is disappearing. It means operators need better evidence, better timelines, and better integration between application telemetry and domain-level data. When **Site Monitoring**, **Website Performance**, **Site Availability**, and **Domain Database** intelligence are connected, teams can diagnose issues faster, reduce downtime, and make more informed operational decisions without waiting for customers to report a problem.
5. API endpoints used by mobile apps or partners That sequence reflects where business impact is usually greatest. ## Why domain intelligence and uptime data now intersect The internet used to separate infrastructure monitoring from domain administration. That split is fading. Attackers increasingly target the control plane: registrars, DNS records, certificates, and account recovery paths. At the same time, outages are often traced back to simple domain issues rather than deep application failures. This is where a well-maintained **Domain Database** becomes valuable beyond inventory. It supports asset management, renewal workflows, brand protection, and incident triage. If monitoring flags a sudden drop in **Site Availability**, teams can quickly verify whether the problem is rooted in hosting, DNS, or registrar status instead of wasting time on the wrong layer. ## What strong monitoring programs get right The best teams treat monitoring as an operational habit, not a dashboard accessory. They review false positives, tune thresholds by business criticality, and test alert routing regularly. They also align alerts with user impact, because a five-second slowdown on a marketing page matters less than a 500-millisecond delay on a payment API. A practical, resilient setup usually includes: – geographically distributed checks – alert escalation by severity – dependency mapping for third-party services – certificate and domain expiry warnings – performance baselines before major releases – incident review tied to customer outcomes ## The next phase: from detection to prediction The direction of the market is clear. Monitoring is shifting from simple detection to prediction. Machine learning is being used to identify anomaly patterns before they become incidents, and infrastructure teams are increasingly automating remediation for common failures. With cloud-native systems, where services may scale across regions in seconds, manual oversight alone is no longer enough. That does not mean human judgment is disappearing. It means operators need better evidence, better timelines, and better integration between application telemetry and domain-level data. When **Site Monitoring**, **Website Performance**, **Site Availability**, and **Domain Database** intelligence are connected, teams can diagnose issues faster, reduce downtime, and make more informed operational decisions without waiting for customers to report a problem.